AMD should be gifting their GPUs by the dozens to the most prolific Open Source contributors if they want a piece of the cake. Their lack of access to CUDA is really harming them badly.
It's more than just that: for the money, their consumer GPUs don't compete in compute tasks (especially inference/training) and their Linux compute drivers are a pile of steaming garbage on consumer hardware. It's really interesting/depressing to watch as they've done a nice job of supplying good open source graphics drivers. They really seem to be lacking something at a leadership level in terms of understanding GPU compute outside of specific enterprise/scientific use cases.
I think that is underselling the big, slow push of their heterogeneous compute architecture. I don't understand the things, but as far as I can read it they've got 3.6GFLOP [0] GPU on those things as of 2022.
Nvidia are effortlessly crushing AMD right now and as far as I can tell it is because they implemented a bunch of BLAS functions on the GPU (it is weirdly difficult to get a good tutorial on how to do matrix multiplication on an AMD GPU; every so often I look for one and have I think literally never found an example). But strategically, AMDs approach to GPU-CPU memory fusion is probably going to be the technically stronger approach. Assuming it works.
In hindsight they should have focused on libraries to let people use their GPU, but big picture they clearly understand how important it is to embrace general purpose compute and are treating it as a high priority.
> But strategically, AMDs approach to GPU-CPU memory fusion is probably going to be the technically stronger approach. Assuming it works.
I mean if anything, Nvidia is already there and crushing it too. CUDA has a unified memory model on Linux today and has for years, so if you have a proper pointer created by cudaMallocManaged, it can be used transparently in both GPU and CPU code without cudaMemcpy. And on the Grace Hopper chip, the open-source driver supports heterogeneous memory management, giving both the CPU and GPU unified, coherent memory across the CPU and GPU even though they have completely separate and isolated memory chips; 512GB LPDDR5X versus 96GB HBM3. This coherency is granular down to the cache line, too. So now every memory allocator and every system call and pointer can be passed directly to the GPU or from GPU to CPU freely.
And the open source driver supports HMM on normal x86_64/aarch64 Linux with consumer-level GPUs today, btw, but it's not as fast or granular. And then there are platforms like Jetson which have used single memory pools for a while; Orin uses a single shared bank of LPDDR5X chips for both CPU and GPU and will get HMM at some point in the future too I assume, though it uses a different driver.
Honestly the only place AMD seems to be winning in terms of compute is on large, bespoke contracts and features like unlocked FP64 performance with parts that are unobtanium and software stacks that have dedicated support engineers. Even Intel seems to be putting up more of a direct fight against Nvidia with oneAPI...
> And ... the Grace Hopper chip ... supports heterogeneous memory management
That is the point though, isn't it? Nvidia and AMD are converging to the same model, so it isn't fair to say AMD doesn't understand GPU compute. Nvidia just had a much neater implementation path where they hacked together something that worked in software while their hardware team figured out how to actually implement it. Technically it is arguable that they're behind AMD on general GPU compute, although that'd be pedantic given how thoroughly AMD failed to get their customers a place in the GPGPU market for the last decade.
AMD is floundering, no question. But the failure was understanding the path-dependent implementation aspects. They do understand that GPU compute is essential to the future of computing as an industry. They're clearly putting a lot of resources into that vision and they have been for around 20 years (similar timeline to CUDA).
> as far as I can tell it is because they implemented a bunch of BLAS functions on the GPU
rocBLAS and other vendor agnostic numeric libraries have made a lot of progress in the past 2 years (mostly as a result of the DoE's exascale computing project)
If progress means going from nothing however long ago to hardlocking my system today then progress achieved. But for me rocBLAS has not yet reached the lofty peaks of multiplying matricies together.
In fairness, my graphics card isn't supported - multiplying matricies being one of those advanced features that they only implemented in the last couple of years. Older graphics cards maybe don't have the grunt for that.</sarcasm>
I love AMD, the linux graphics drivers are great. But their GPGPU platform is not good.
I’ve only used it on MI200 series cards but both direct API in C and through a cupy interface for matrix mul and triangular solves it’s worked well for me. There was a bit of bugginess for running on non-default streams a few months back, but seems fixed now.
Now AMDs platform for debugging and profiling GPGPUs apps on the other hand is a different story/mess and very very behind NVIDIAs solutions.
For sure the lack of consumer card support is annoying, all effort seems focused on satisfying their contracts and not expanding support into the much wider GPGPU market rn and I wish it wasn’t. It feels like an afterthought at times. I just wanna be able to compile and play around with HIP on my home computer, but :(
> (it is weirdly difficult to get a good tutorial on how to do matrix multiplication on an AMD GPU; every so often I look for one and have I think literally never found an example).
I'd think their leadership is aware. Likely they are just picking their battles to be in strategic areas where they'll capture the most revenue to resource-investment. AMD has a lot of catching up to do and they cannot compete on all fronts at once.
Usually when I see this, it symptomatic of major organizational dysfunction of some type. One time, I was in a firm where 100% of the energy was spent on quarterly objectives for some executive bonus pay structure. No one cared if the organization lived or died, since there were always other jobs.
Nothing AMD is doing in the GPU space is aligned with long-term survival or competitiveness.
No, they've become a general compute company selling pickaxes for whatever the current goldrush tends to be. Now it's AI, yesterday it was crypo-currencies, the day before is was PC games and video editing.
They've been trying to push their GPUs as CPU alternatives everywhere especially in the datacenters where their presence grew since the acquisition of Mellanox. They also tried to acquire ARM, to squeeze both Intel and AMD out of the CPU market completely.
I hate what they've done to the PC gamers, but as a company trying to grow in more markets and make even more money, they've executed insanely well strategically, leaps ahead of AMD.
I mean their public messaging is pure AI now, but I also think they have been very smart about running the right direction since Alexnet came out and showed what you could do with a GPU.
People want to rent the pricey NVIDIA DGX H100. So Google just put it in their DC, letting customers pay its full price it every ~3 months; plus they don't have to operate it, which is win (or is it ?).
I wish that humanity gets to harvest static energy one day, so that everyone is able to run the experiments required in large-scale deep learning research, not only a handful of deep pocketed organizations.
> Each A3 supercomputer is packed with 4th generation Intel Xeon Scalable processors backed by 2TB of DDR5-4800 memory. But the real "brains" of the operation come from the eight Nvidia H100 "Hopper" GPUs, which have access to 3.6 TBps of bisectional bandwidth by leveraging NVLink 4.0 and NVSwitch.
Interestingly the "4th generation Intel Xeon Scalable processors" themselves have up to 2.45 TBps in memory bandwidth, with the 8-socket configuration, or 2 TBps with 2-socket Xeon Max and HBM. If they'd make an 8-socket Xeon Max it would have 8 TBps.
Considering that the Xeon Max 9462 is $8000 vs. the H100 going for north of $40,000, that could be interesting.
The throughput these gpu's have make the price pretty competitive, but I think AMD is working on a APU in their instinct lineup. That could be pretty competitive since Nvidia is overcharging for memory and you could just use sticks instead
A lot of this is workload-dependent. LLMs for example seem to be memory-bound, so a fast CPU with HBM or a large number of memory channels should do well.
Socket SP5 has 12 channels, which is 461 GBps per socket at DDR5-4800. Intel is getting 1 TBps from HBM, but then you're paying for HBM. $8000 for the cheapest Xeon Max vs. $3000 for the Epyc 9334 with the same number of cores or ~$1000 for the least expensive thing that will fit in the 12-channel socket. CPUs also have a cost advantage because then you don't need a CPU and a GPU.
Other things might be more compute bound. Then a fast GPU in a socket with a lot of memory channels worth of cheap sticks should be fun.
Only if you're purely 100% compute bound by a wide margin versus the size of your working set. But in that scenario, you can just widen the memory interface, lower the clocks speeds, and you'll normally still come out ahead in efficiency. Most datacenter parts are going to prefer such a route.
The physical integrity needed for extremely high bandwidth interfaces is just really tough to achieve on a DIMM-like slot without really advanced high-channel socket topologies. Those numbers listed before aren't for nothing; 2.4TBps bandwith for an 8-socket Xeon vs 2.0Tbps with a 2-socket Xeon using HBM2 is a very significant improvement in overall efficiency.
Given "supercomputer" isn't an agreed upon term, and this single server is significantly higher performance than anything most people get to use, the claim isn't that bad.
TPUs were supposed to be their unfair advantage in the cloud ML/DL space. But from what I've experienced, and have heard from other engineers, there's always some subtle incompatibility with TPUs that requires modifying the training/eval scripts. I wonder why they didn't try to polish the rough edges with Pytorch, et al.
If they're admitting TPUs aren't their competitive advantage, then why not sell it to other hosting providers, or hell, even directly to ML scientists and enthusiasts? They'll finally get economies of scale, and take business (and mind share) away from NVidia's monopoly.
There's a few comments to this effect in the thread, and I don't entirely understand where they're coming from. There's nothing in the article suggesting they've changed their strategy with TPUs in any way. The word TPU isn't even mentioned here. There's no suggestion they're actually using this internally either. There's no benchmarks showing that it's more cost-effective or scales better.
And isn't your second paragraph the obvious reason for why this product (A3) exists? It's something they expect to sell to cloud customers who have an existing GPU-based workflow, and just want to run it as-is as fast/cheap/scalable as possible, without worrying about compatibility, and making sure they can always move the workload to some other cloud provider or on-prem if needed.
It's like suggesting Sony releasing some of their games on the PC means they're deprecating Playstation.
(Maybe there would be more details in the IO talk. Does anyone know which one this announcement is from?)
A sentence that reads "I am going to eat nothing but vegetables from now on" doesn't mention meat, but you can infer that I won't eat meat again from the sentence.
A sentence that says Google are going all in on nVidea GPUs for AI doesn't need to mention TPUs to convey information about their future either.
> A sentence that reads "I am going to eat nothing but vegetables from now on" doesn't mention meat, but you can infer that I won't eat meat again from the sentence.
TBF, there is no mention of anything remotely similar to "I am going to eat nothing but vegetables from now on".
Sure. That's why I mentioned multiple ways in which the article could have been relevant to TPUs, which you chose not to quote. But it didn't have any of those either. The sentence you're offering up as a demonstration is just something you made up that does not appear in the article.
If anything, this just reinforces the point I was making. There is nothing at all in the article supporting this narrative. So, where is this coming from? Why are you so intent on this idea that you're reduced to fabricating support for it?
At the very least we know that there's a team in Google that chose to build an AI supercomputer with non-Google hardware. They didn't, or wouldn't, work with the TPU team to do it, or they did and the TPU team couldn't get it to work. Or they could but something still made nVidia hardware more compelling. Every level of management involved were persuaded that this was the case even knowing it would send a message to people outside of Google about TPUs.
Andnfrom.all that we're meant to say it infers nothing about TPUs?
Companies never announce change of direction like you seem to think. There is no positive outcome in doing so. Instead they announce the new thing and promise to continue to support the old thing and then just don’t.
>There's nothing in the article suggesting they've changed their strategy with TPUs in any way
Google owns and designs their own TPUs. They offer these TPUs in the cloud. I've seen many comments in here about how next-level TPUs are (despite zero evidence indicating that). Google even disclaims their TPU by saying that you shouldn't compare it with the H100 given node levels et al.
Their premiere offering is an nvidia H100 offering.
Yes, of course this is a pretty telling indication. If Google was all in on TPUs they'd be building mega TPU systems and pushing those. Instead they're pushing nvidia AI offerings.
> I wonder why they didn't try to polish the rough edges with Pytorch, et al.
It's always funny to me when people have this blindspot - because TPUs aren't for you, they're for the ads org. Neither are PyTorch nor TF for that matter. They're more than happy to get external bug fixers but trust me those individual teams dgaf about external customers. They're not in the least bit community driven projects.
This is for GCP. Google themselves probably still trains on custom hardware but they don't offer their latest and greatest hardware on GCP.
Offering more options to customers is always better especially when Nvidia has great market share in this area. This is probably the reason why Microsoft is trying to help AMD catch up so their is more competition. AI GPU prices are insane compared to standard GPU because of the lack of competition.
This is thinking about the issue all wrong. Google's internal infrastructure is terrifyingly large. They won't "get scale" by selling TPUs. That would expand the scale of TPUs only slightly.
And they want to support people migrating from other cloud providers where they are already using nvidia/Cuda. Though it also helps support the opposite migration, they are the smaller cloud player trying to get customers, not the big one trying to constrain them as much yet.
Looking back at the promises made at I/O 2022, most of the products were released timely (for instance, Docs auto-summary, an AI feature, came out in March for Workspace), although some could be in a better spot:
- Immersive mode in Maps (also AI, using NeRF) has only recently added just 5 cities,
- The screenshot-then-Multisearch Near Me is technically shipped, but it seems super-rough; I screenshot my keyboard and it suggested a specific brand of pasta across nearby supermarkets,
- I am still waitlisted for access to LaMDA through the AI test kitchen (and given this year’s I/O, things seem to take a different direction).
There is no question that ChatGPT’s release in particular went by a more successful playbook comparatively.
These were available right at announcement time and not wait listed, I was using them while the keynote was still going on. The lists are for other products & wrappers around the foundational models.
I haven't seen otter or unicorn models, nor can I find tune them yet.
I think in this case they just know the demand is RED HOT and they don't have nearly the supply to go around. I don't think it's really the typical new product concerns on this one (product-market fit, are we covering use cases, are there technical problems, etc.). They know people want this and would rather have it right this second, problems and all, than wait for a slow rollout; Google just doesn't have the supply to go around.
Imagine if Apple when launching a new iPhone would first launch to a small country for testing, like Philippines or something, and then slowly expand worldwide. That would drive consumers nuts.
And my main worry is: are they just going to cancel the new thing that my company invested six months and $250,000 of engineering time integrating with…
Probably doesn't matter that much because it's just hardware. Presumably not that hard to run your software on another intel box with nvidia GPUs. There's also plenty of demand for nvidia GPUs right now, still no guarantee given it's Google, but it would be hard not to make money with this.
I don't know of a single GCP product that's been shut down, although I could be missing something. But their track record for GCP is, I think, what you would want a cloud provider's record to be.
(I should mention that I work for GCP. But this is just based on my own memory.)
The greatest technological advancement in recent years critically depends on the hardware from a single company with no competition. yet Nvidia stock is still below its 2021 peak. How so?
It doesn't necessarily depend on Nvidia hardware. Nothing stops you from training an AI on an adequately advanced ASIC or FPGA, in theory. Nvidia does accelerate it though, and they're also offering unparalleled performance-per-dollar to the audience that's in the market.
In a way, it feels like Nvidia is embarrassingly aware of this. They were the reluctant shovel salesman during the cryptocurrency gold rush, and they're rightfully wary of going all-in on AI. If I was an investor, I'd also be quantifying just how much of a "greatest technological advancement" modern machine learning really is.
It's the ecosystem - everyone else is using CUDA, so you need a very good incentive to stray away from that ecosystem. a x2-3 cost of hardware won't justify such move.
The cryptomarket was less favorable to Nvidia because it harmed the loyal customers (gamers, AI) for a temporary market (crypto) that indeed largely declined.
This narrative has been pushed for several years now with the likes of Habana, Cerebras, SambaNova, Graphcore, Tesla Dojo, etc.
And yet none of them seem to have made any dent in Nvidia’s dominance. None of them have any real presence on industry-standard MLPerf benchmarks (not even TPU releases all benchmarks and they started the damn benchmark).
The truth is that making an AI chip isn’t as simple as putting a bunch of matmuls together in a custom ASIC and pointing a driver at it; there’s hard work and optimization the entire stack down, many of which aren’t even focused on the math part.
So while I don’t doubt that some competitors (AMD?) will gain decent market share eventually, Nvidia’s probably not going to be displaced so easily.
Because making decisions on account of an asset's price being higher 2 years ago is just falling victim to price anchoring? Would Nvidia not be worth buying in 2020 because its price was much lower in 2018 and thus must be overvalued in 2020?
Investments should be based on the actual value of the company relative to its price, as well as relative to other investment oppertunities. Trying to making a profit by trading based on historical stock prices will get you whipped by quants who are already doing a much better job of that sort of thing than you could ever hope to do.
But the question isn't "can I do better than teams of quants who do this 100 hrs/wk and are supported by institutions with effectively infinity dollars", but "can I make money on this"? If I buy NVDA at 283, will it go up? There's no guarantee it will, they could lose their edge to AMD and the GPU market could bottom out, but barring some calamity, the answer seems to be yes they well. There maybe other stocks out there that are better buys, but they're part of the SP500 for a reason.
That's a broader question, but in general: it doesn't matter what I think about Nvidia's business. I could be correct all the way, but if other people disagree with me, they won't pay me for the shares.
It's also not necessarily about the 2021 peak but why isn't Nvidia bigger? allegedly it's a necessary component to a technology that can replace hundreds of millions of people (worth trillions in economic output). And unlike OpenAI, Nvidia wins no matter which company wins the model competition.
As far as stock prices, there was a hype cycle paired with government handouts to the people, these combined to push tech stocks to unreasonable valuations.
Why not? They seem to be a lot of leeway before any specific company will find it cheaper to design their own chips, or even to move to AMD (ROCm is not as well supported).
Perhaps someone like OpenAI has both the expertise and incentive to do so, but not many others.
So if you think that maybe OpenAI has other options if NVDA increases their prices why do you think that one of the other big names ( MSFT,GOOG,IBM,TSLA,AMD,INTC,Facebook ) also cannot do the same thing?
I guess for the same reason most of them keep buying from Intel - their market position allows them to pass on the cost to their customers, so it's not worth the distraction.
OpenAI is more of a "one-(very impressive)-trick-pony", so they have a stronger incentive.
A significant part of the 2021 peak may be explained by the crypto craze from which Nvidia benefited greatly and which has almost completely vanished since.
Thinking about it, it’s hard to believe how fast the hype cycle moved on from crypto. Only 1-2 years ago every media person, influencer, YouTuber, tweeter etc. were talking about/selling/shilling some kind of crypto, and now all of it seems to have moved on to AGI doomsaying.
Cryptocurrencies still had high barriers for entry for the public at large - not really a means of payment, and high risk as an investment.
Generative AI is used by millions, has very low barrier for entry (it's even free!) and most importantly does not require a network effect so can be valuable immediately.
Surprisingly, they left that out of their sales pitch.
With LLMs everyone+dog is coming out of the woodwork to let people know that it will lead to the extinction of the species.
Not that I don’t think generative AI is a lot more useful than crypto and deserves (some of) the hype. The problem is the hucksters jumping on the hypetrain to continue their $new_hotness grift.
This is why Leading Edge Node will continue to be well funded. Consumer Electronics ( Mainly Smartphone ) Silicon usage has been the main push behind the development of Pure Play leading edge foundry in the past 10 years. Despite the predicted / expected drop of Smartphone sales, considering the potential shown by ChatGPT or Bard, GPU or Wafers dedicated for AI will continue to be in demand for at least another 5 years. In terms of lead time into the investment of silicon development that means we can continue to expect progress all the way till 2030, either 1nm or 0.8nm.
Can you elaborate on the supposed “wonky physics” that goes on when things get small? I’ve seen it thrown around that 3nm is “almost” the smallest size that can be made before different classes of physical errors are introduced due to the extremely small distance between gates.
Read [1] from 2020, I have replied there along with the economics issues I was referring to which AI demand will likely solve, or at least part of the solution.
I have yet to see a proposal for compute-in-memory that isn’t actually compute-near-memory and keeps the density of memory arrays.
If you’re still doing row-column access, it’s just another Von Neumann machine. If you have compute hardware within each row to perform operations on every row in parallel, it’s now just another ALU.
I think HP has all the patents on these. Maybe when their patents expire some company that can actually release a product will make good use of them instead of having a business model consisting of bricking printers that use off-brand ink.
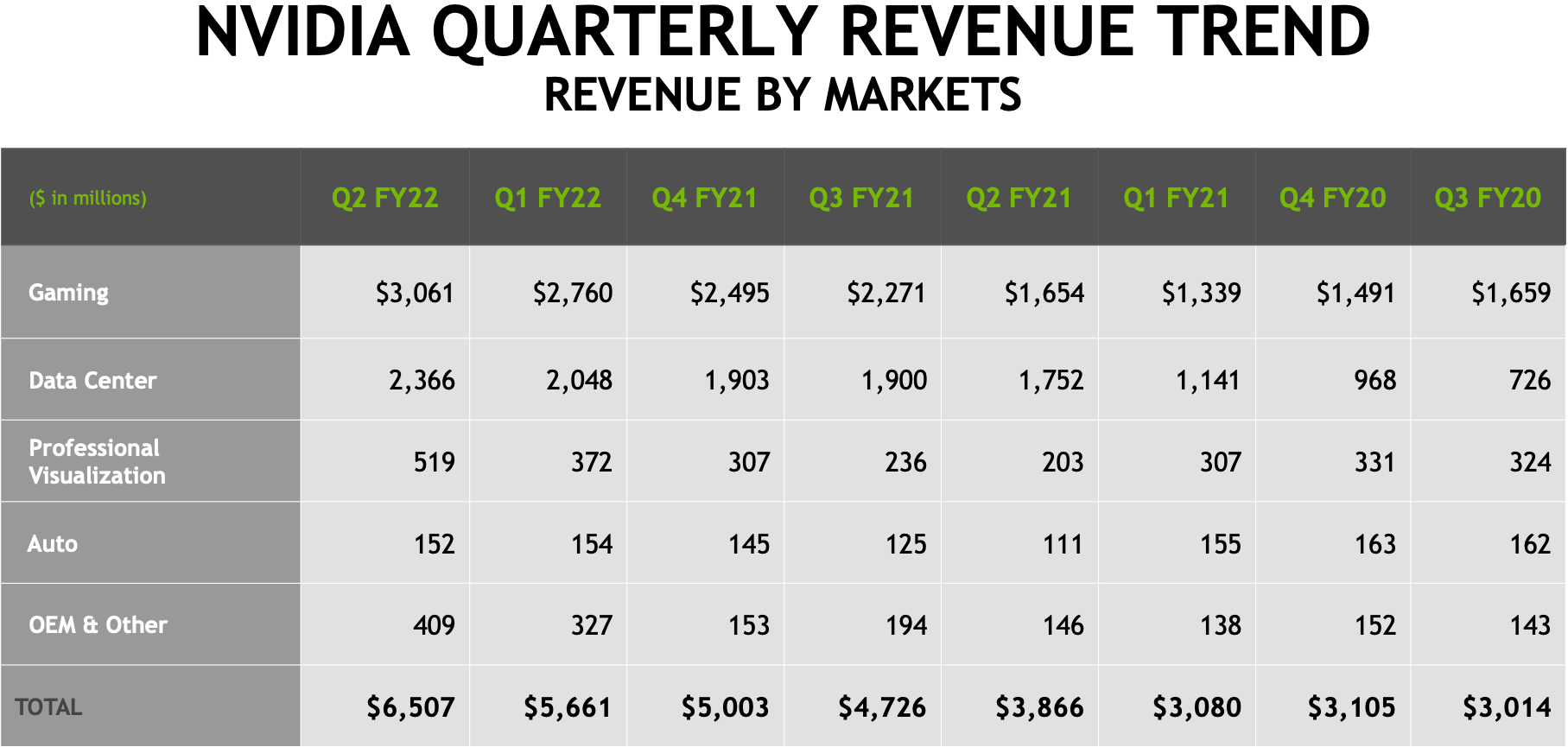
So this is why Nvidia isn't lowering the price on the GPUs despite them sitting on the shelves and not selling. They make enough money from customers in the data center and supercomputer businesses that gaming is just a small market.
Gaming is a huge chunk of their revenue, around $2B in recent quarters, with datacenter around $3.5B.
Despite the AI hype, Nvidia’s datacenter revenue was down QoQ and only up 10% YoY.
It remains to be seen if the growth trajectory has changed meaningfully over the last quarter, because the stock is priced for massive earnings growth while their revenue and earnings have been actually shrinking.
>Gaming is a huge chunk of their revenue, around $2B in recent quarters, with datacenter around $3.5B.
Is it? I remember hearing they didn't make much money from their consumer GPU products a few years back. This was one of the reasons why they tried to clamp down so aggressively on people using desktop GPUs for computing. They had made a number of driver changes which restricted the capabilities of anything but the tesla and quadro products. They were also restricting bulk purchases of their cards.
I bought a desktop in New York City a month ago with a Nvidia RTX 4090 card at Best Buy - 4090 being the most powerful Nvidia card Best Buy had in stock. At that time (a month ago) there were several desktops with this card in stock around the city, and I bought the one I wanted (if I had more time my purchase might have been different).
Looking right now - I don't see any unbundled Nvidia RTX 4090 cards for sale at Best Buy in New York City that you can go and pick up today. I don't see any desktops with 4090 cards that you can pick up today. I do see one Best Buy in New York City has one laptop with a 4090 card.
Looking at Best Buy in Los Angeles - I see one desktop with a 4090 for sale in West LA that can be picked up today. I don't see any unbundled 4090 cards for sale or laptops with 4090 cards.
I don't know if Nvidia lower end GPUs are sitting on shelves and not selling, but it doesn't look like Nvidia's higher end GPUs are sitting on shelves and not selling.
Microcenter here in Overland Park, Kansas had at least one of each of the major brands of 4090s available for sale in store last week when I was there. Do people go to Best Buy to buy ultra high end graphics cards? I haven’t bought a graphics card at Best Buy since they used to scam people by putting “pro” at the end of a worse product back in 2003 or so.
H100s are not sitting on shelves, even at the 35kUSD price sticker. Consumer GPUs, probably yes. Even for datacenter compute workloads that would not go for H100, the L40 is supposedly 3xA40 in FP32 FLOPs but still on the same memory bandwidth, so who knows what kind of performance you'll get whenever you can get your OEM to build you one......
No, it is the 9,163,584th [0] indication that Google likes to pursue multiple solutions in the same space in parallel with different submarkets, risk profiles, expected payoff terms, or other dimensions.
this looks like it's for GCP. TPUs are used for most internal workloads.
It's available externally but some of the papercuts and devex without the TPU/TF team helping you can be more painful than using Nvidia/CUDA
TPUs do compete with GPUs for ML tasks, so yes, this is evidence that GPUs are winning.
The only alternative I could imagine is that TPUs will "win" at supercomputers exclusivity aimed at inference (as opposed to training). Since TPUs excel at inference. The question is how much ML compute is used for inference as opposed to training. Not much, I guess, otherwise something like TPUs would be more popular.
I've heard estimates that the amount of compute used to train GPT-4 is equivalent to 8 months of usage and most models are used much less than GPT-4 is, although I guess they are also easier to train.
They have published various papers and technical reports. The main aim is to make them inhouse and more efficient. Each generation is a little different, like (iirc) v3 is not for training, more for serving at inference time. The use different floating point format and circuits, so they are not good for scientific workloads, iirc again.
Different workloads require different infrastructure.
Can your workload saturate the TPU without getting throttled by memory or network? Great! Use TPUs and reduce training cost.
But if your TPUs are idle 70% of the time because the constraint is getting data to them ...
"A3 represents the first production-level deployment of its GPU-to-GPU data interface, which allows for sharing data at 200 Gbps while bypassing the host CPU. This interface, which Google calls the Infrastructure Processing Unit (IPU), results in a 10x uplift in available network bandwidth for A3 virtual machines (VM) compared to A2 VMs."
TPU's have a TPU-TPU interconnect that is faster and lower latency than any GPU cluster [1]. That said this is a huge leap for GPU's on GCP. For A100's SOTA is 1.6tbit per host over Infiniband (which azure and some smaller gpu clouds provided), AWS had 400-800 Gbit and GCP had .... ~100gbit.
SOTA seems to be 3.2Tbit for H100 clusters so this still seems a bit slow? (Tricky as they don't give us a clear number just 10x). H100's are much more powerful per chip though so at least initially the clusters will be smaller and not network bound.
The tricky thing is no one other than Azure of the big providers seems willing to pay Nvidia's margins for RDMA switches, it seems this is still the case.
That's why I said "most" and "overall". Of course TPUs will have a niche. But it looks like the vast majority of money spent on ML compute is converging on GPUs.
Interesting, so what is the compute power of the 1000-node A100 super cluster my team has been allocated at work? I was expecting Google to be much bigger than us.
Back of the envelope math is that H100 is twice as fast as A100 (task may vary). So your 1000-node A100 very, very fast.
Now, the GPU-to-GPU links (NVLink) might often give them a big advantage for some workloads, letting them exchange data without going through the CPU, and virtually address more memory if your want to manipulate very large models.
So it's hard to answer properly without knowing the topology of your cluster.
Also, note that this "supercomputer", is probably "just" a DGX H100 in Google's DC.
They use their own TPUs like described in this paper [0]. They talk about 4096-chip supercomputers so this should give you an idea about what we are talking here. The paper is pretty fascinating stuff. They are using optical interconnects for example, which sounded like science fiction a few years ago.
Apples and oranges to an extent. 1) Knowledge is being derived from said energy use, and 2) nerds aren't extremely bitter that they didn't pick up that millionaire-making space cash when it was handed to them on a platter, before the rest of the world, a handful of years ago.
{kind=link}